Background:
Idena is a “Proof-of-Person blockchain” as described on its website. Compared to Bitcoin where the original idea is “one CPU one vote”, now every person in the physical world enjoys only one vote in the Idena network. This makes it possible for ordinary users to mine coins at home without having to purchase power-consuming dedicated miners or servers.
Idena created a novel way to prove the humanness and uniqueness of on-chain identities. It asks all the users around the world to participate in an AI-hard turing test at the same time. That means you can only pass the test by yourself and are not able to maintain multiple valid identities because software just won’t help to pass the exam which is simple for human to solve (choose between two sets of 4 pictures the one that tells a meaningful story rather than nonsense).
Once you pass the turing test you can start to mine DNA coins. Just leave your computer always on and keep the Idena node software online. However, if you’re mining with a desktop machine it probably will comsume extra power or if you use a laptop you’ll be offline when you want to take it to other places. So this is the point where Raspberry Pi comes in.
According to the official FAQ, the minimum configuration for an Idena node to run is as follows:
- Linux/x64
- 1 CPU core
- 2 Gb RAM
- 100 Gb HDD
- 100 Mbps uplink
The new Raspberry Pi 4B will definitely do the job for us. It’s a credit-card sized computer that only costs $45 for the 2GB RAM version. It’s so small that even if you turn it on 24*7 it consumes very little power. The blockchain data for Idena network now is quite small and isn’t growing too rapidly so I don’t think you’ll need a 128GB microSD for storage. Just pick a 32GB one and you’ll be fine. In this tutorial, I’ll use Raspberry Pi 4B as an example to show you how to run Idena node on it to mine DNA coins. Of course you can choose the 4GB or 8GB RAM version and use it with larger SD card such as 128GB if you plan to use it for other purposes in the future.
Steps:
Let’s assume that you have successfully set up your Raspberry Pi 4 according to the official tutorial and have installed Ubuntu on it following the official guide. Now let’s move on to the Idena part!
1. Compile idena node from source
The idena-go repo doesn’t provide pre-built binaries for arm architectures so we have to compile it from source. Since it’s written in golang, we first install go:
~$ sudo apt install golang-go
Then pull the source code to local directory:
~$ git clone https://github.com/idena-network/idena-go.git
Enter into the directory and build. Because we later need the frontend to know which version of idena node we’re currently running, it’s necessary to add a version number when compiling. Usually we mark it as the same version as the latest release (e.g., 0.21.3).
~$ cd idena-go/
~$ go build -ldflags "-X main.version=0.21.3"
When it’s done you’ll see the executable in the current working directory. Let’s move it out and give it a new name:
~$ mv idena-go ../idena-node-arm64-0.21.3
Before running the node, put the recommended configure file into the same directory with the node executable file.
~$ cd ../
~$ wget https://idena.io/examples/guide-remote-1/config.json
~$ ./idena-node-arm64-0.21.3 --config=config.json
You’ll see it running and outputting status messages into the CLI. Press Ctrl + C to terminate the node. You don’t want to run the node like this because the process may be accidentally killed for various reasons which leads to mining penalty for being offline, so we need another program to protect the process.
2. Use supervisor to daemonize idena node
Supervisor is a great tool to make Idena node run in the background without interruptions. Installing is easy with just one line of command on Ubuntu:
~$ sudo apt install supervisor
Then edit the supervisor configuration file for Idena. Create a config file and open it with your favourite editor (“nano” here for example).
~$ sudo nano /etc/supervisor/conf.d/idena.conf
Paste the following block into the config file and press Ctrl + X to exit and then press “Y” and then the “Enter” key to save.
[program:idena]
command=/home/ubuntu/idena-node-arm64-0.21.3 --config=config.json
directory=/home/ubuntu/
autostart=true
autorestart=true
stderr_logfile=/var/log/idena/error.log
stdout_logfile=/var/log/idena/stdout.log
user=ubuntu
Now we start supervisor first and then tell supervisor to start idena:
~$ sudo supervisord
~$ sudo supervisorctl
supervisor> update
You’ll see supervisor reporting idena RUNNING. If your Raspberry Pi is powered off accidentally, Idena will automatically be started when you power on the machine again.
Note: remember to open port 40405 if you are behind a router/firewall.
3. Connect to the node with front-end
Now your Idena node is running in the background and we need a UI to connect to it for more convenient interactions. Grab the latest release here for your OS and install it .
Before running the front-end program, we need to get two parameters. On Raspberry Pi you’ll find an automatically created directory called datadir. reveal the API key in it by issuing this command:
~$ cat ./datadir/api.key
Then we build an ssh tunnel for the front-end to connect to the Idena node. On your desktop machine run the following command. This is for Linux and Mac OS. Windows users can use third-party tools such as Putty.
~$ ssh -L 9998:localhost:9009 [email protected]
Where 192.168.1.2 is the internal IP address of your Raspberry Pi. Replace it with your own. Now let’s open idena-desktop that we just installed.
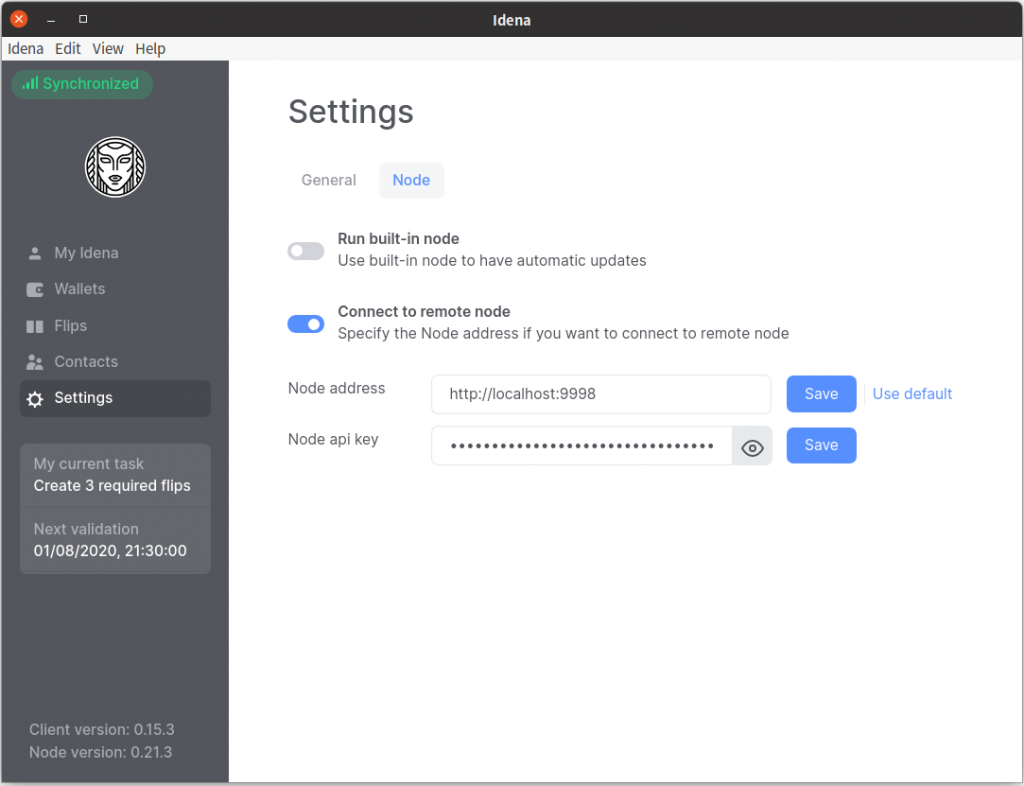
Click “Settings” –> “Node”, switch off “Run built-in node” and switch on “Connect to remote node”. In the Node address box input: http://localhost:9998 and in the Node api key box just copy and paste the API key we got in the last step.
Now you should be connected to the node. Leave it running for some time, depending on the blockchain size and your bandwidth, and you’ll see a green sign on the top-left corner indicating that you’ve caught up to the latest block.
What’s next? Validate your identity by participating in the Turing test and then turn on the mining option in idena-desktop. Your Raspberry Pi will mine DNA coins 24*7 for you! Go to Idena website to explore more on this project.