原理很简单,豆瓣小站的网页HTML看了一下,每首歌的名字和地址都写好了在里面,只是每次载入地址是不一样的而已。用urllib读取一下,分析出里面的名字和地址,然后下载即可。
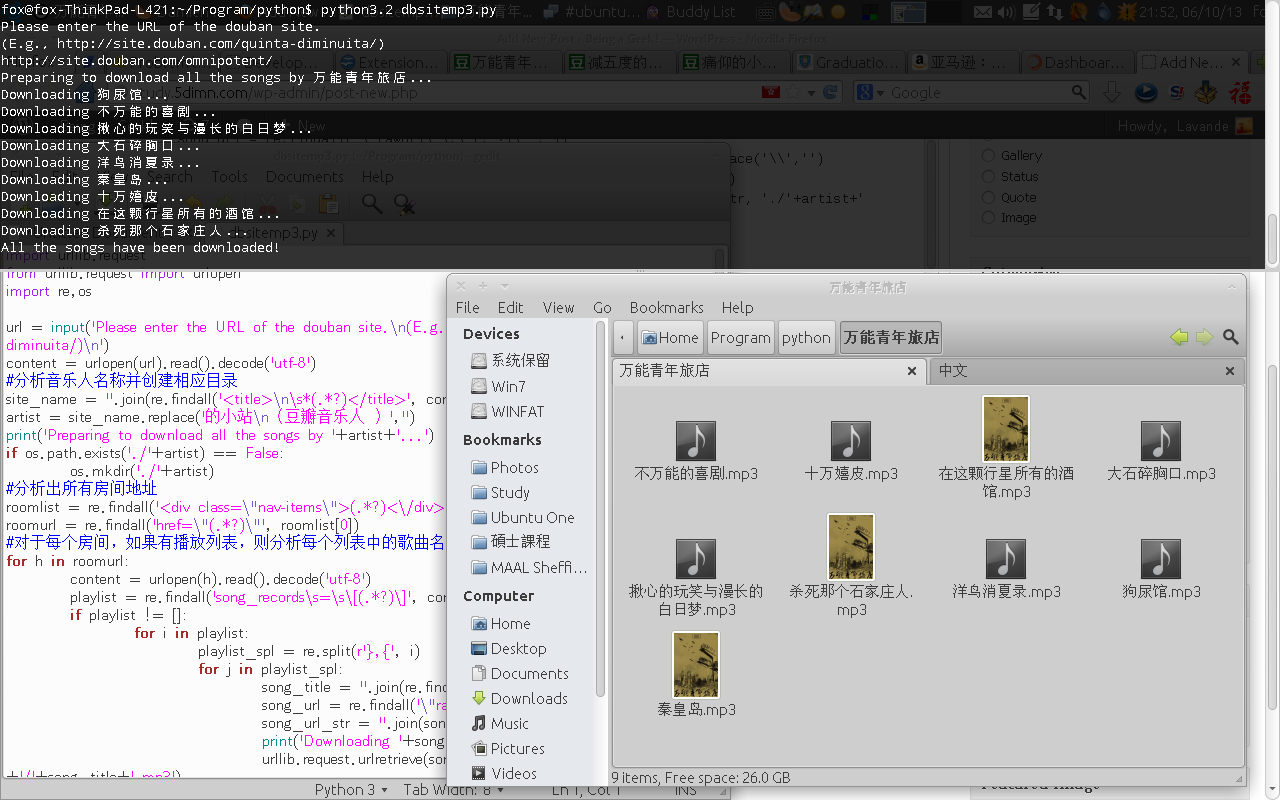
先看效果图,上面是命令行的运行结果,左边是代码,右边是拖回来的文件,成就感满满!
最后附上python3.2示例代码:
import urllib.request
from urllib.request import urlopen
import re,os
url = input('Please enter the URL of the douban site.\n(E.g., http://site.douban.com/quinta-diminuita/)\n')
content = urlopen(url).read().decode('utf-8')
#分析音乐人名称并创建相应目录
site_name = ''.join(re.findall('<title>\n\s*(.*?)</title>', content, re.DOTALL))
artist = site_name.replace('的小站\n(豆瓣音乐人)','')
print('Preparing to download all the songs by '+artist+'...')
if os.path.exists('./'+artist) == False:
os.mkdir('./'+artist)
#分析出所有房间地址
roomlist = re.findall('<div class=\"nav-items\">(.*?)<\/div>', content, re.DOTALL)
roomurl = re.findall('href=\"(.*?)\"', roomlist[0])
#对于每个房间,如果有播放列表,则分析每个列表中的歌曲名和对应地址,然后下载
for h in roomurl:
content = urlopen(h).read().decode('utf-8')
playlist = re.findall('song_records\s=\s\[(.*?)\]\;\n', content, re.DOTALL)
if playlist != []:
for i in playlist:
playlist_spl = re.split(r'},{', i)
for j in playlist_spl:
song_title = ''.join(re.findall('\"name\"\:\"(.*?)\"', j))
song_title = ''.join(song_title).replace('\\','')
song_title = ''.join(song_title).replace('/','.')
song_url = re.findall('\"rawUrl\"\:\"(.*?)\"', j)
song_url_str = ''.join(song_url).replace('\\','')
filepath = './'+artist+'/'+song_title+'.mp3'
if os.path.isfile(filepath) == False:
print('Downloading '+song_title+'...')
urllib.request.urlretrieve(song_url_str, filepath)
else:
print(song_title+' alreadly exists. Skipped.')
print('All the songs have been downloaded (if there are any). Enjoy!')